PK 설계: 자연키(Natural Key) vs 대체키(Surrogate Key)
1. Surrogate PK가 유리한 이유
1-1. InnoDB 클러스터 인덱스 구조
MariaDB/MySQL의 InnoDB는 PK 기준으로 데이터를 물리적으로 정렬(Clustered Index)한다.
- Auto-increment 정수: 항상 순차 삽입 → 페이지 분할(page split)이 거의 없음 → INSERT 성능 우수
- UUID/긴 문자열 자연키: 랜덤 위치 삽입 발생 → 페이지 분할 빈번
1-2. JOIN 성능
FK로 참조하는 다른 테이블에서도 동일한 값을 저장해야 하므로, 정수 PK는 JOIN 시 비교 연산이 빠르고 FK 컬럼도 작다.
1-3. 자연키의 불변성 보장 불가
"절대 안 바뀐다"고 생각한 자연키(이메일, 주민번호, 도메인 등)가 비즈니스 요건 변경으로 바뀌는 경우가 실무에서 흔하다. PK가 바뀌면 모든 FK를 연쇄 수정해야 하는 문제가 생긴다.
2. 자연키를 PK로 써도 괜찮은 경우
- 매핑 테이블(M:N 관계):
(user_id, role_id)같은 복합키가 그 자체로 의미가 있고, 별도 auto PK를 추가해도 어차피 UNIQUE 제약이 필요하면 오히려 낭비 - 키 크기가 작고 불변이 확실한 경우: ISO 국가 코드(
CHAR(2)) 같은 표준 코드값이 PK인 lookup 테이블 - 삽입보다 조회 위주이고 자연키로만 조회하는 경우: surrogate PK를 쓰면 오히려 자연키 조회 시 보조 인덱스 → PK 인덱스 이중 탐색이 생긴다
성능 테스트
조건
- 측정: 20만 행 / 200만 행에서
INSERT속도와 저장공간을 비교 - AUTO_INCREMENT: PK 값은 DB가 동일 규칙으로 생성(순차 증가)
- 환경
- python: 3.14
- mariadb: 11
- 동일 데이터: PK 전략이 달라도 payload 동일하게 저장되며, 차이는 PK/인덱스 구조에서 발생
| 식별자 | PK 구조 | 보조 인덱스 | VARCHAR 삽입 순서 |
|---|---|---|---|
| INT_AI 단독 | INT AUTO_INCREMENT | 없음 | 순차 |
| BIGINT_AI 단독 | BIGINT AUTO_INCREMENT | 없음 | 순차 |
| INT_AI + UNIQUE | INT AUTO_INCREMENT | UNIQUE VARCHAR(N) | 순차 |
| BIGINT_AI + UNIQUE | BIGINT AUTO_INCREMENT | UNIQUE VARCHAR(N) | 순차 |
| VARCHAR PK 순차 | VARCHAR(N) | 없음 | 순차 |
| VARCHAR PK 랜덤 | VARCHAR(N) | 없음 | 랜덤(셔플) |
insert 속도 및 저장 공간 비교
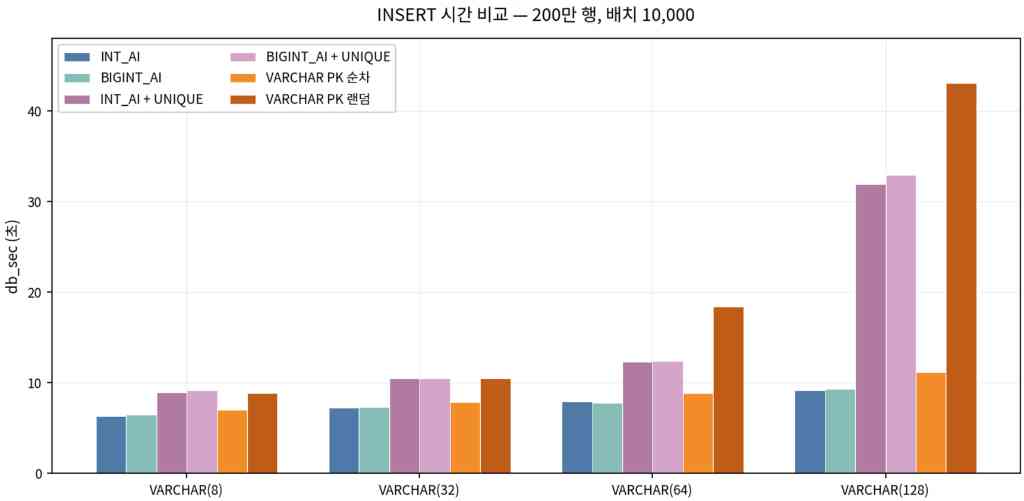
- VARCHAR PK는 순차일경우 Auto Increment에 근접하지만 랜덤은 N이 클수록 페이지 분할·리프 재배치 비용이 커져 Insert 시간이 가장 크게 벌어진다
- PK를 Auto Increment로 두더라도 UNIQUE VARCHAR(N)커질수록 긴 문자열 유일성 인덱스 유지가 INSERT 경로를 무겁게 만든다.
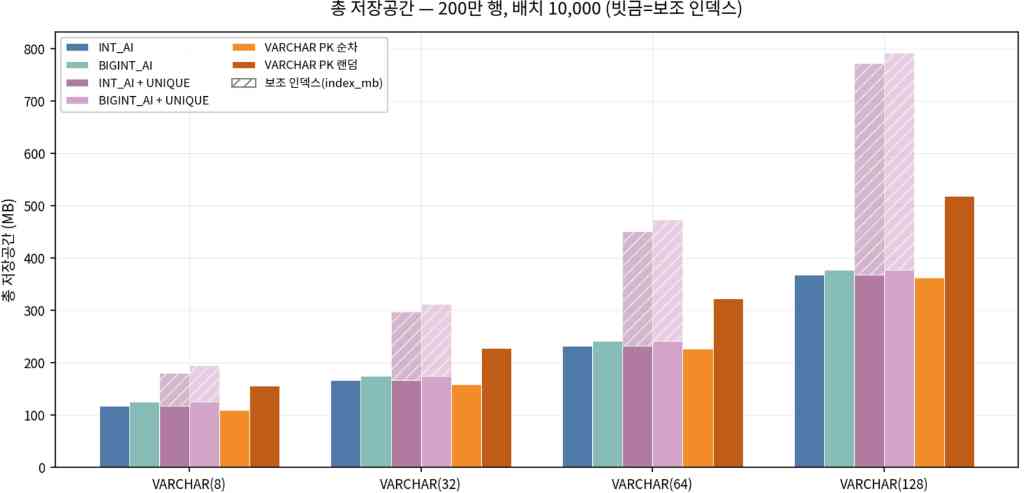
- VARCHAR PK 랜덤은 리프 중간 삽입·페이지 분할이 잦아져 같은 200만 행이어도 순차보다 물리 용량이 크게 잡힌다.
- UNIQUE는 PK와 별도의 보조 B-Tree라서, 행 외에 유니크 키와 내부적으로 PK 값이 한 번 더 저장되어 용량이 크게 증가한다.
배치에 따른 속도 비교
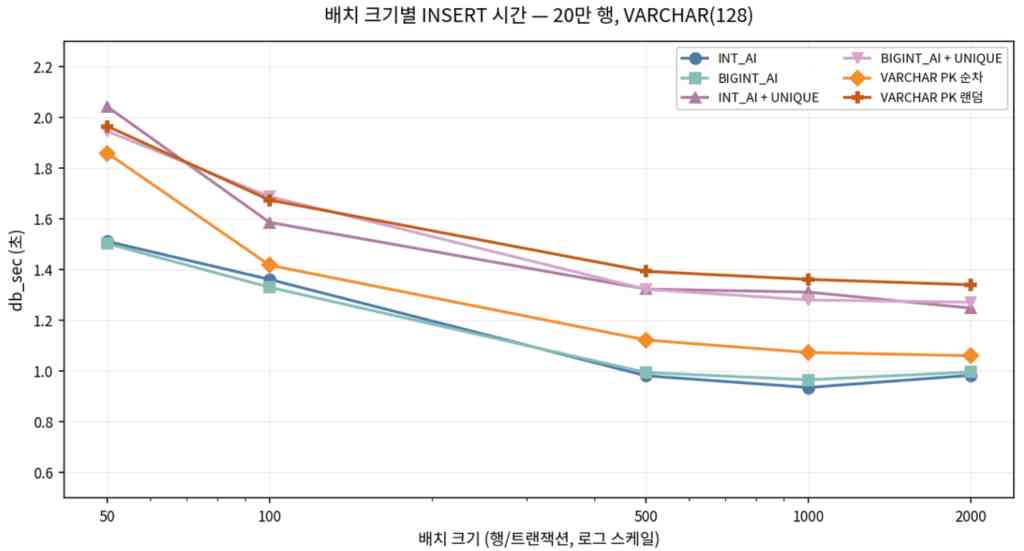
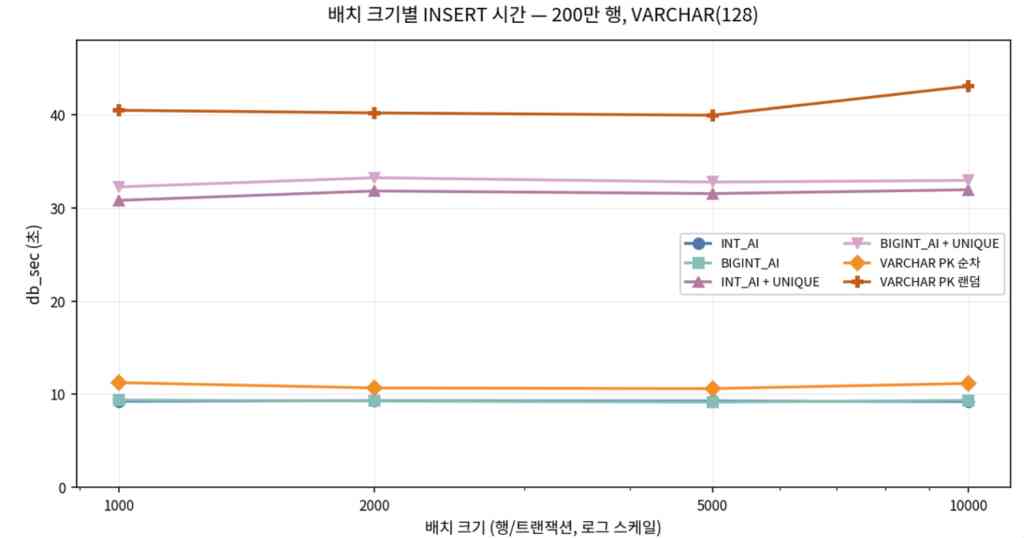
- 200만건 기준 배치수 1,000이나 10,000의 속도 차이가 없고 split, disk flush, redo/undo log가 병목이 된다.
데이터 10배 증가 시 INSERT 시간 스케일링
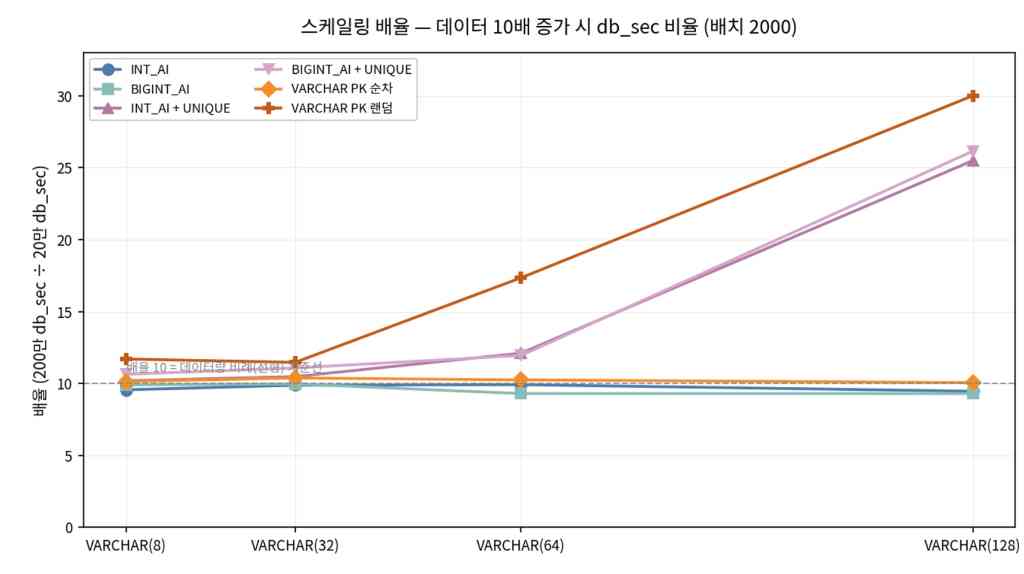
- PK 순차는 VARCHAR(N) 축이 바뀌어도 비율이 대략 10 근처에 머물러, 이 구간에서는 스케일링이 비교적 예측 가능하다.
- VARCHAR PK 랜덤은 N이 커질수록 10을 크게 넘어 10배 데이터에 시간이 10배 이상”으로 악화된다
- UNIQUE도 128에서 약 25~26대로 선형보다 무겁다.
처리량과 행당 저장 비용
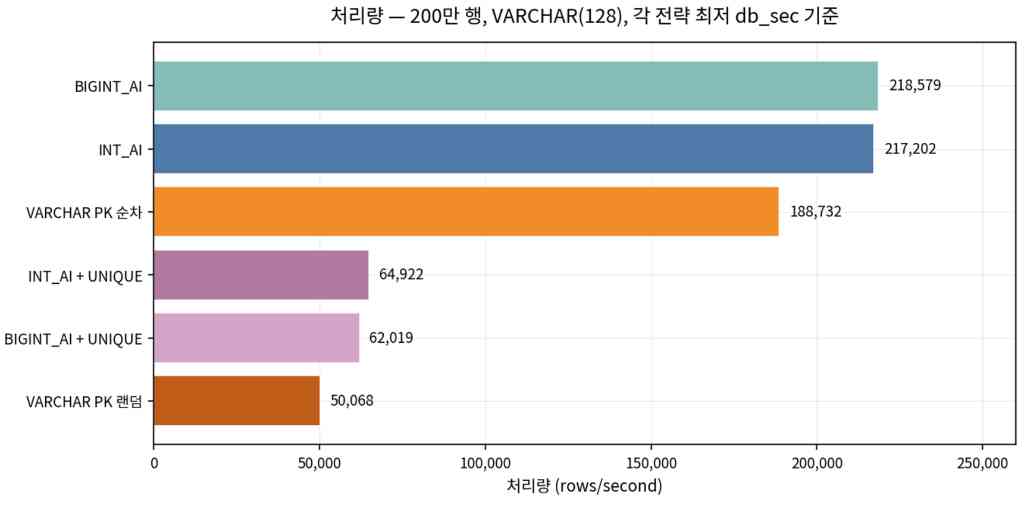
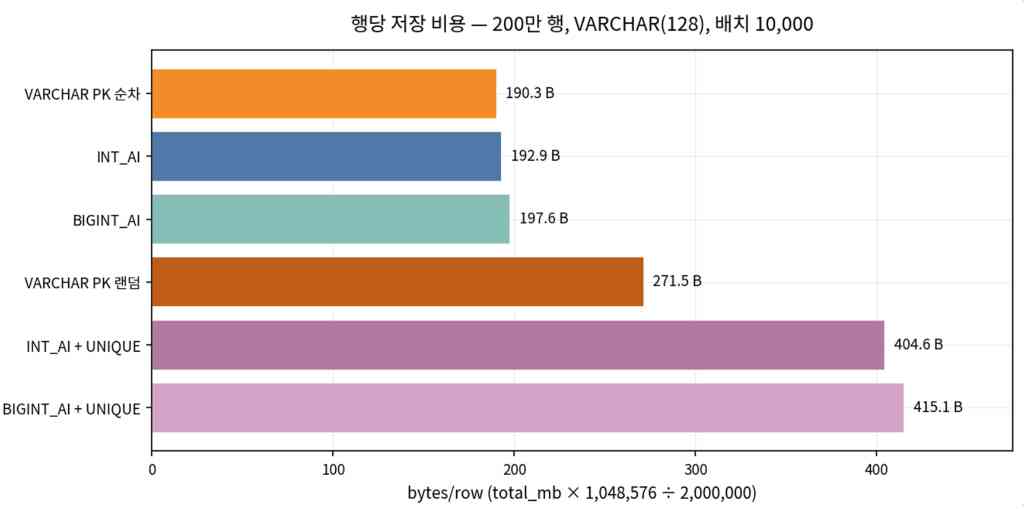
제한 조건 (측정되지 않은 항목)
위 실험은 INSERT 소요 시간과 저장 공간에 초점이 맞춰져 있다.
아래 항목은 원 측정·보고서 범위에 포함되지 않았다.
| 구분 | 측정에 포함되지 않은 내용 |
|---|---|
| SELECT | PK 단일 조회, 보조 인덱스 조회, 범위 스캔, ORDER BY까지 포함한 조회 비용 |
| JOIN | FOREIGN KEY 참조를 포함한 다중 테이블 조회 |
| UPDATE / DELETE | 갱신·삭제 경로의 성능 |
| 다중 보조 인덱스 | 실무 테이블처럼 보조 인덱스가 여러 개일 때의 저장 공간·삽입 비용 |
| 동시성 | 다수 클라이언트 동시 INSERT, AUTO_INCREMENT 락 경합, 버퍼 풀 경합 |
| 캐시 미스 | 버퍼 풀 용량을 넘는 데이터셋에서의 디스크 I/O 영향 |
| 규모 외삽 | 20만·200만 행 밖의 데이터 규모에서의 동작 |
200만개 기준 원본 표에서 batch = 2000인 행만 모은 발췌
| VARCHAR 길이 | PK 전략 | 순차/랜덤 | db_sec | data_mb | index_mb | total_mb |
|---|---|---|---|---|---|---|
| 8 | INT_AI | sequential | 6.466 | 117.625 | 0.000 | 117.625 |
| 8 | BIGINT_AI | sequential | 6.535 | 125.672 | 0.000 | 125.672 |
| 8 | INT_AI + UNIQUE | sequential | 8.754 | 117.625 | 64.641 | 182.266 |
| 8 | BIGINT_AI + UNIQUE | sequential | 9.000 | 125.672 | 68.641 | 194.312 |
| 8 | VARCHAR PK 순차 | sequential | 6.989 | 109.656 | 0.000 | 109.656 |
| 8 | VARCHAR PK 랜덤 | shuffled | 9.321 | 157.766 | 0.000 | 157.766 |
| 32 | INT_AI | sequential | 7.285 | 167.672 | 0.000 | 167.672 |
| 32 | BIGINT_AI | sequential | 7.351 | 174.719 | 0.000 | 174.719 |
| 32 | INT_AI + UNIQUE | sequential | 10.327 | 167.672 | 131.000 | 298.672 |
| 32 | BIGINT_AI + UNIQUE | sequential | 10.483 | 174.719 | 136.000 | 310.719 |
| 32 | VARCHAR PK 순차 | sequential | 7.994 | 158.953 | 0.000 | 158.953 |
| 32 | VARCHAR PK 랜덤 | shuffled | 10.286 | 229.000 | 0.000 | 229.000 |